This is what it looks like overnight. It’s not as fun when you’re actually in the middle of using it.
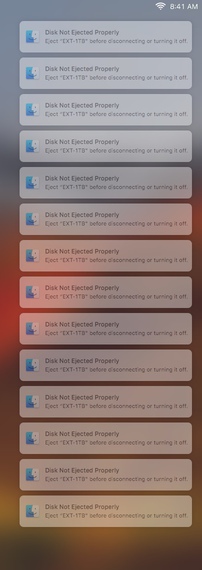
This is what it looks like overnight. It’s not as fun when you’re actually in the middle of using it.
I’ve been hoarding data for more than 20 years. For backups, I used to burn a CD periodically, but I long since ran over those limits. Today, my backups are hard drives. One reason is that I’ve moved between computers several times during that period, and when I do, I find stuff I don’t know what to do with. So I copy all that data into a new folder, typically called something like temp/backup/that-system-name/tmp/old/save/keep/t.files/save.d.
After 20 years, that starts to add up. So I’ve been looking at programs to help me find and get rid of duplicates. (I’ve been using rsync -n, and occasionally diff -qr, to compare folders. But the problem is deciding what folders, at what places in the directory structure, to compare.)
So I’ve been looking to see what kind of tools are available to help. At this point, I looked at duff, jdupes, and dupd.
So far, I’ve focused on dupd. It does what I was thinking needed to be done: crawl the entire hierarchy and save the result as a database.